Field域
Field属性
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,
Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
是否分词(tokenized)
是:作分词处理,即将Field值进行分词,分词的目的是为了索引。
比如:商品名称、商品简介等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要分词后将语汇单元索引。
否:不作分词处理
比如:商品id、订单号、身份证号等
是否索引(indexed)
是:进行索引。将Field分词后的词或整个Field值进行索引,索引的目的是为了搜索。
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
否:不索引。该域的内容无法搜索到
比如:商品id、文件路径、图片路径等,不用作为查询条件的不用索引。
是否存储(stored)
是:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取。
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
否:不存储Field值,不存储的Field无法通过Document获取
比如:商品简介,内容较大不用存储。如果要向用户展示商品简介可以从系统的关系数据库中获取商品简介。
Field常用类型
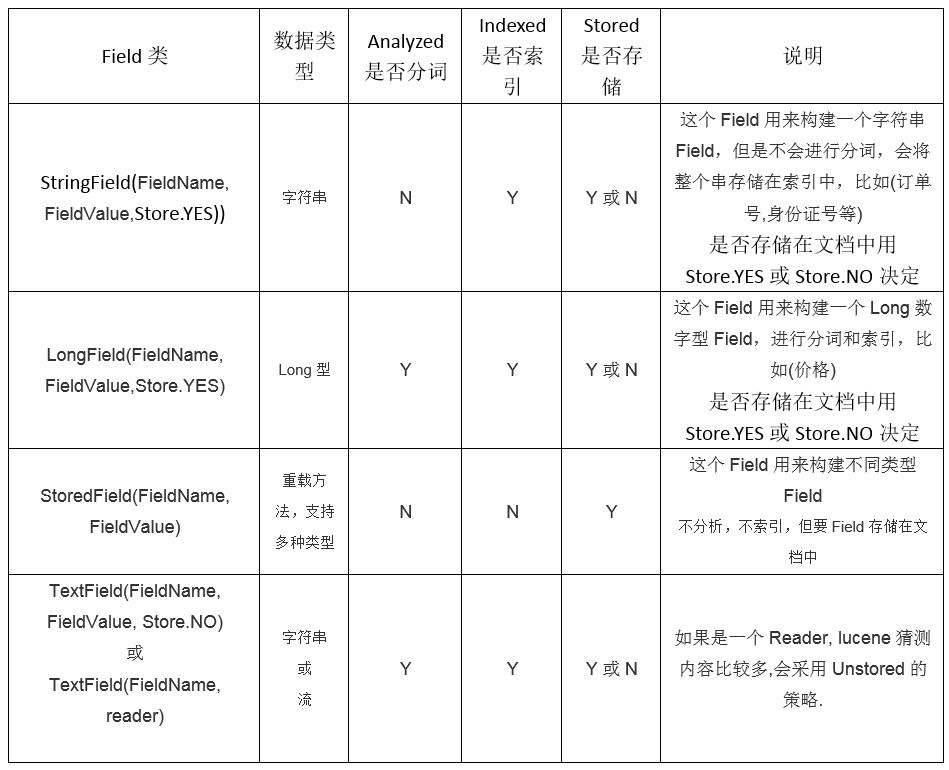
Field代码说明
图书id:
是否分词:不用分词,因为不会根据商品id来搜索商品
是否索引:不索引,因为不需要根据图书ID进行搜索
是否存储:要存储,因为查询结果页面需要使用id这个值。
图书名称:
是否分词:要分词,因为要将图书的名称内容分词索引,根据关键搜索图书名称抽取的词。
是否索引:要索引。
是否存储:要存储。
图书价格:
是否分词:要分词,lucene对数字型的值只要有搜索需求的都要分词和索引,
因为lucene对数字型的内容要特殊分词处理,本例子可能要根据价格范围搜索,需要分词和索引。
是否索引:要索引
是否存储:要存储
图书图片地址:
是否分词:不分词
是否索引:不索引
是否存储:要存储
图书描述:
是否分词:要分词
是否索引:要索引
是否存储:因为图书描述内容量大,不在查询结果页面直接显示,不存储。
不存储是来不在lucene的索引文件中记录,节省lucene的索引文件空间,如果要在详情页面显示描述,思路:
从lucene中取出图书的id,根据图书的id查询关系数据库中book表得到描述信息。
索引维护
管理人员通过电商系统更改图书信息,这时更新的是数据库,如果使用lucene搜索图书信息需要在数据库表book信息变化时及时更新lucene索引库。
添加索引
调用 indexWriter.addDocument(doc)添加索引。
参考入门程序的创建索引。
删除索引
private IndexWriter getWriter(){
try {
//3.进行分词
Analyzer analyzer = new StandardAnalyzer();
//4.创建indexWriter
//4.1创建Directory 目录流
IndexWriterConfig indexconfig = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//Directory 是抽象类,有两个实现类,FSDirectory(文件系统) RAMDirectory(内存)
Directory directory = FSDirectory.open(new File("F:\\index"));
return new IndexWriter(directory,indexconfig);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
@Test
public void deleteIndex() throws Exception{
IndexWriter writer = getWriter();
writer.deleteDocuments(new Term("name","神"));
//6.关闭IndexWriter
writer.close();
}
修改索引
更新索引是先删除再添加,建议对更新需求采用此方法并且要保证对已存在的索引执行更新,可以先查询出来,确定更新记录存在执行更新操作。
// 修改索引
@Test
public void updateIndex() throws Exception {
// 1、指定索引库目录
Directory directory = FSDirectory.open(new File("F:\\index"));
// 2、创建IndexWriterConfig
IndexWriterConfig cfg = new IndexWriterConfig(Version.LATEST,
new StandardAnalyzer());
// 3、 创建IndexWriter
IndexWriter writer = new IndexWriter(directory, cfg);
// 4、通过IndexWriter来修改索引
// a)、创建修改后的文档对象
Document document = new Document();
// 文件名称
Field filenameField = new StringField("filename", "updateIndex", Store.YES);
document.add(filenameField);
// 修改指定索引为新的索引
writer.updateDocument(new Term("filename", "apache"), document);
// 5、关闭IndexWriter
writer.close();
}
搜索
创建查询的两种方法
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法。类似关系数据库Sql语法一样,Lucene也有自己的查询语法,
比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
可通过两种方法创建查询对象:
1)使用Lucene提供Query子类
Query是一个抽象类,lucene提供了很多查询对象,比如TermQuery项精确查询,NumericRangeQuery数字范围查询等。
如下代码:
Query query = new TermQuery(new Term("name", "lucene"));
2)使用QueryParse解析查询表达式
QueryParser会将用户输入的查询表达式解析成Query对象实例。
如下代码:
QueryParser queryParser = new QueryParser("name", new IKAnalyzer());
Query query = queryParser.parse("name:lucene");
通过Query子类搜索
TermQuery
TermQuery项查询,TermQuery不使用分析器,搜索关键词作为整体来匹配Field域中的词进行查询,比如订单号、分类ID号等。
private void doSearch(Query query) {
IndexReader reader = null;
try {
// a) 指定索引库目录
Directory indexdirectory = FSDirectory.open(new File(
"F:\\index"));
// b) 创建IndexReader对象
reader = DirectoryReader.open(indexdirectory);
// c) 创建IndexSearcher对象
IndexSearcher searcher = new IndexSearcher(reader);
// d) 通过IndexSearcher对象执行查询索引库,返回TopDocs对象
// 第一个参数:查询对象
// 第二个参数:最大的n条记录
TopDocs topDocs = searcher.search(query, 10);
// e) 提取TopDocs对象中的文档ID,如何找出对应的文档
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
System.out.println("总共查询出的结果总数为:" + topDocs.totalHits);
Document doc;
for (ScoreDoc scoreDoc : scoreDocs) {
// 文档对象ID
int docId = scoreDoc.doc;
doc = searcher.doc(docId);
// f) 输出文档内容
System.out.println(doc.get("filename"));
System.out.println(doc.get("path"));
System.out.println(doc.get("size"));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
@Test
public void testTermQuery() throws Exception {
// 1、 创建查询(Query对象)
Query query = new TermQuery(new Term("filename", "apache"));
// 2、 执行搜索
doSearch(query);
}
NumbericRangeQuery
NumericRangeQuery,指定数字范围查询.
@Test
public void testNumbericRangeQuery() throws Exception {
// 创建查询
// 第一个参数:域名
// 第二个参数:最小值
// 第三个参数:最大值
// 第四个参数:是否包含最小值
// 第五个参数:是否包含最大值
Query query = NumericRangeQuery.newLongRange("size", 1l, 100l, true,true);
// 2、 执行搜索
doSearch(query);
}
BooleanQuery
BooleanQuery,布尔查询,实现组合条件查询。
@Test
public void booleanQuery() throws Exception {
BooleanQuery query = new BooleanQuery();
Query query1 = new TermQuery(new Term("id", "3"));
Query query2 = NumericRangeQuery.newFloatRange("price", 10f, 200f,
true, true);
//MUST:查询条件必须满足,相当于AND
//SHOULD:查询条件可选,相当于OR
//MUST_NOT:查询条件不能满足,相当于NOT非
query.add(query1, Occur.MUST);
query.add(query2, Occur.SHOULD);
System.out.println(query);
search(query);
}
组合关系代表的意思如下:
1、MUST和MUST表示“与”的关系,即“并集”。
2、MUST和MUST_NOT前者包含后者不包含。
3、MUST_NOT和MUST_NOT没意义
4、SHOULD与MUST表示MUST,SHOULD失去意义;
5、SHOUlD与MUST_NOT相当于MUST与MUST_NOT。
6、SHOULD与SHOULD表示“或”的概念。
通过QueryParser搜索
通过QueryParser也可以创建Query,QueryParser提供一个Parse方法,
此方法可以直接根据查询语法来查询。Query对象执行的查询语法可通过System.out.println(query);查询。
QueryParser
代码实现
@Test
public void testQueryParser() throws Exception {
// 创建QueryParser
// 第一个参数:默认域名
// 第二个参数:分词器
QueryParser queryParser = new QueryParser("name", new IKAnalyzer());
// 指定查询语法 ,如果不指定域,就搜索默认的域
Query query = queryParser.parse("lucene");
System.out.println(query);
// 2、 执行搜索
doSearch(query);
}
查询语法
1、基础的查询语法,关键词查询:
域名+“:”+搜索的关键字
例如:content:java
2、范围查询
域名+“:”+[最小值 TO 最大值]
例如:size:[1 TO 1000]
注意:QueryParser不支持对数字范围的搜索,它支持字符串范围。数字范围搜索建议使用NumericRangeQuery。
3、组合条件查询
Occur.MUST 查询条件必须满足, 相当于and +(加号)
Occur.SHOULD 查询条件可选, 相当于or 空 (不用符号)
Occur.MUST_NOT 查询条件不能满足, 相当于not非 -(减号)
1)+条件1 +条件2:两个条件之间是并且的关系and
例如:+filename:apache +content:apache
2)+条件1 条件2:必须满足第一个条件,忽略第二个条件
例如:+filename:apache content:apache
3)条件1 条件2:两个条件满足其一即可。
例如:filename:apache content:apache
4)-条件1 条件2:必须不满足条件1,要满足条件2
例如:-filename:apache content:apache
第二种写法:
条件1 AND 条件2
条件1 OR 条件2
条件1 NOT 条件2
MultiFieldQueryParser
通过MuliFieldQueryParse对多个域查询。
@Test
public void testMultiFieldQueryParser() throws Exception {
// 可以指定默认搜索的域是多个
String[] fields = { "name", "description" };
// 创建一个MulitFiledQueryParser对象
QueryParser parser = new MultiFieldQueryParser(fields, new IKAnalyzer());
// 指定查询语法 ,如果不指定域,就搜索默认的域
Query query = parser.parse("lucene");
// 2、 执行搜索
doSearch(query);
}
TopDocs
Lucene搜索结果可通过TopDocs遍历,TopDocs类提供了少量的属性,如下:
方法或属性 说明
totalHits 匹配搜索条件的总记录数
scoreDocs 顶部匹配记录
注意:
Search方法需要指定匹配记录数量n:indexSearcher.search(query, n)
TopDocs.totalHits:是匹配索引库中所有记录的数量
TopDocs.scoreDocs:匹配相关度高的前边记录数组,scoreDocs的长度小于等于search方法指定的参数n
相关度排序
什么是相关度排序
相关度排序是查询结果按照与查询关键字的相关性进行排序,越相关的越靠前。
比如搜索“Lucene”关键字,与该关键字最相关的文章应该排在前边。
相关度打分
Lucene对查询关键字和索引文档的相关度进行打分,得分高的就排在前边。如何打分呢?Lucene是在用户进行检索时实时根据搜索的关键字计算出来的,分两步:
1)计算出词(Term)的权重
2)根据词的权重值,计算文档相关度得分。
什么是词的权重?
通过索引部分的学习,明确索引的最小单位是一个Term(索引词典中的一个词),
搜索也是要从Term中搜索,再根据Term找到文档,Term对文档的重要性称为权重,
影响Term权重有两个因素:
Term Frequency (tf):
指此Term在此文档中出现了多少次。tf 越大说明越重要。
词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,
如“Lucene”这个词,在文档中出现的次数很多,说明该文档主要就是讲Lucene技术的。
Document Frequency (df):
指有多少文档包含次Term。df 越大说明越不重要。
比如,在一篇英语文档中,this出现的次数更多,就说明越重要吗?
不是的,有越多的文档包含此词(Term), 说明此词(Term)太普通,
不足以区分这些文档,因而重要性越低。
设置boost值影响相关度排序
boost是一个加权值(默认加权值为1.0f),它可以影响权重的计算。
在索引时对某个文档中的field设置加权值高,在搜索时匹配到这个文档就可能排在前边。
在搜索时对某个域进行加权,在进行组合域查询时,匹配到加权值高的域最后计算的相关度得分就高。
设置boost是给域(field)或者Document设置的。
在创建索引时设置
如果希望某些文档更重要,当此文档中包含所要查询的词则应该得分较高,
这样相关度排序可以排在前边,可以在创建索引时设定文档中某些域(Field)的boost值来实现,
如果不进行设定,则Field Boost默认为1.0f。一旦设定,除非删除此文档,否则无法改变。
代码实现
@Test
public void setBoost4createIndex() throws Exception {
// 创建分词器
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_4_10_3,
analyzer);
Directory directory = FSDirectory.open(new File("F:\\index"));
// 创建IndexWriter对象,通过它把分好的词写到索引库中
IndexWriter writer = new IndexWriter(directory, cfg);
Document doc = new Document();
Field id = new StringField("id", "11", Store.YES);
Field description = new TextField("description", "测试设置BOOST值 lucene",
Store.YES);
// 设置boost
description.setBoost(10.0f);
// 把域添加到文档中
doc.add(id);
doc.add(description);
writer.addDocument(doc);
// 关闭IndexWriter
writer.close();
}
中文分词器
什么是中文分词器
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。
而中文则以字为单位,字又组成词,字和词再组成句子。
所以对于英文,我们可以简单以空格判断某个字符串是否为一个单词,
比如I love China,love 和 China很容易被程序区分开来;
但中文“我爱中国”就不一样了,电脑不知道“中国”是一个词语还是“爱中”是一个词语。
把中文的句子切分成有意义的词,就是中文分词,也称切词。我爱中国,分词的结果是:我 爱 中国。
Lucene自带的中文分词器
StandardAnalyzer:
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
使用中文分词器IKAnalyzer
IKAnalyzer继承Lucene的Analyzer抽象类,
使用IKAnalyzer和Lucene自带的分析器方法一样,将Analyzer测试代码改为IKAnalyzer测试中文分词效果。
如果使用中文分词器ik-analyzer,就在索引和搜索程序中使用一致的分词器ik-analyzer。
添加jar包
将 IKAnalyzer0212FF_u1.jar 导入工程
修改分词器代码
// 创建中文分词器
Analyzer analyzer = new IKAnalyzer();
扩展中文词库
从ikanalyzer包中拷贝配置文件到classpath下。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">dicdata/mydict.dic</entry>
<!-- 用户可以在这里配置自己的扩展停用词字典 -->
<entry key="ext_stopwords">dicdata/ext_stopword.dic</entry>
</properties>
如果想配置扩展词和停用词,就创建扩展词的文件和停用词的文件,文件的编码要是utf-8。
注意:不要用记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。
添加扩展词文件:ext.dic,在文件中添加关键字,如:
全文搜索
路神
等等