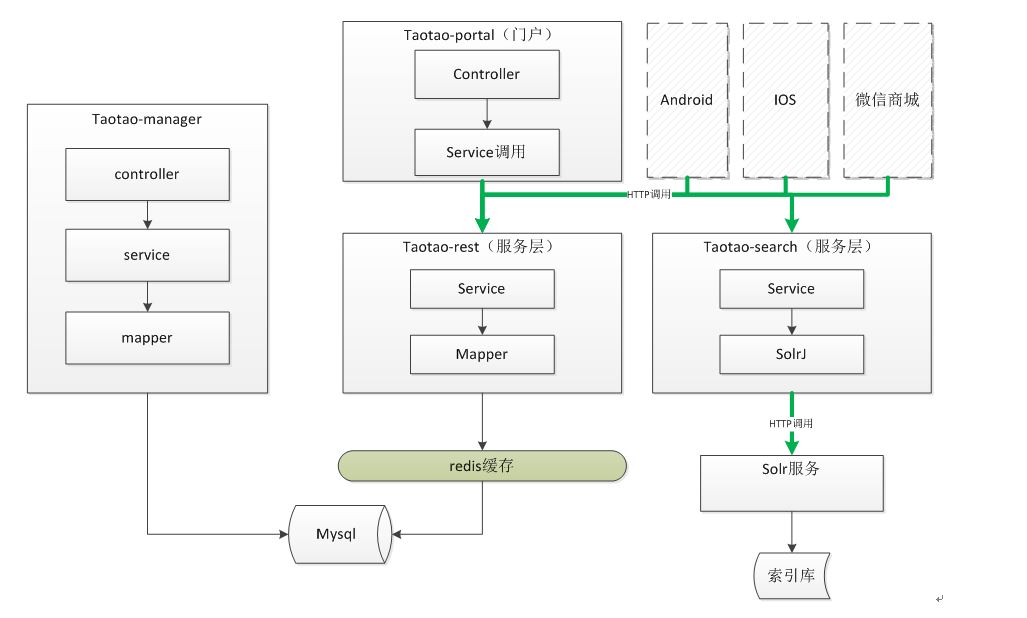
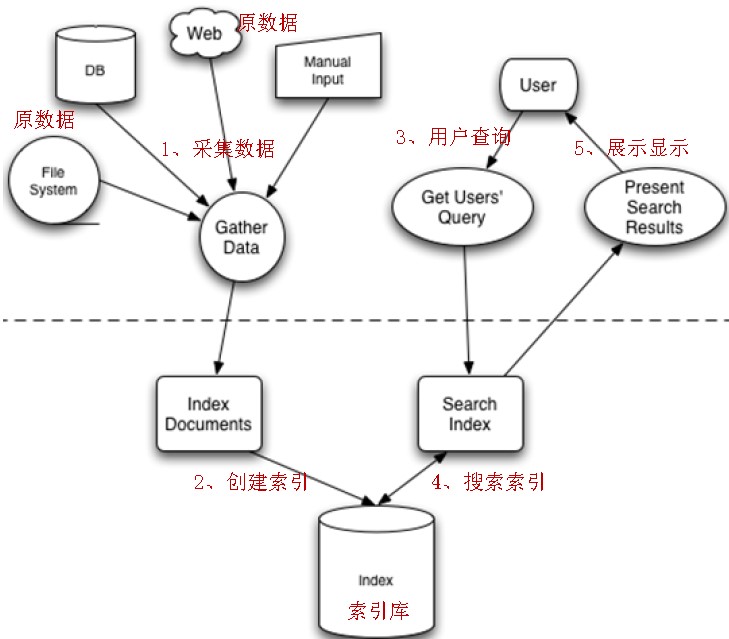
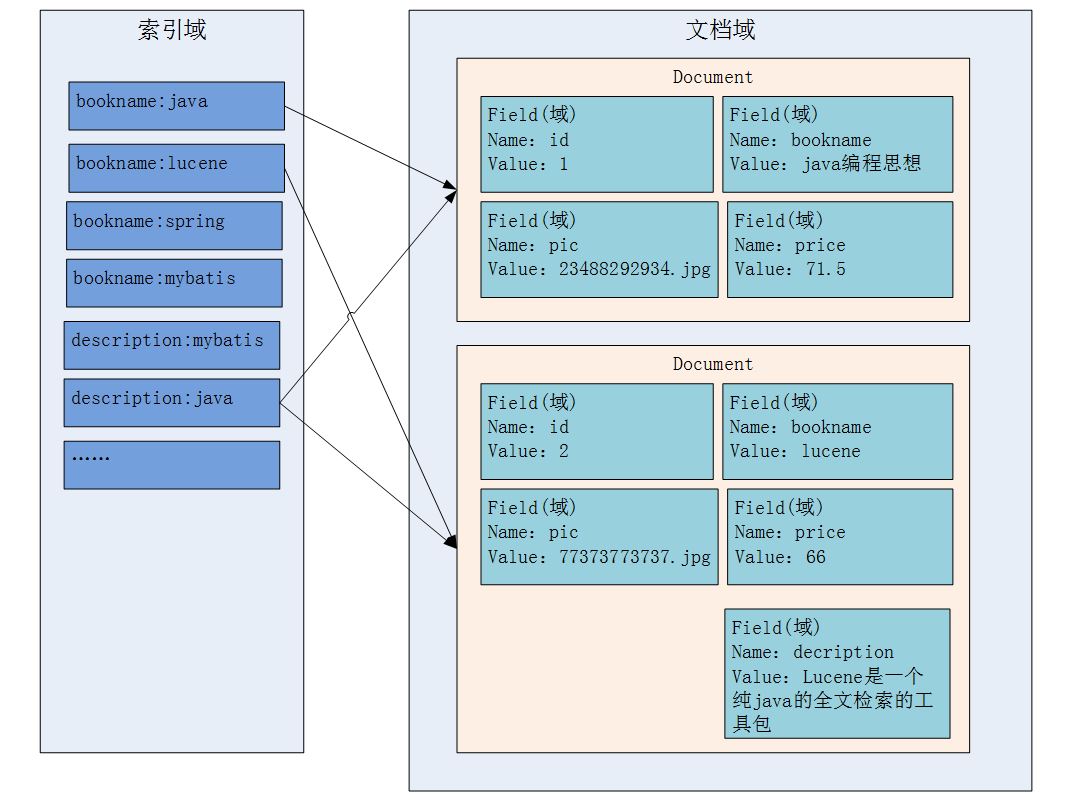
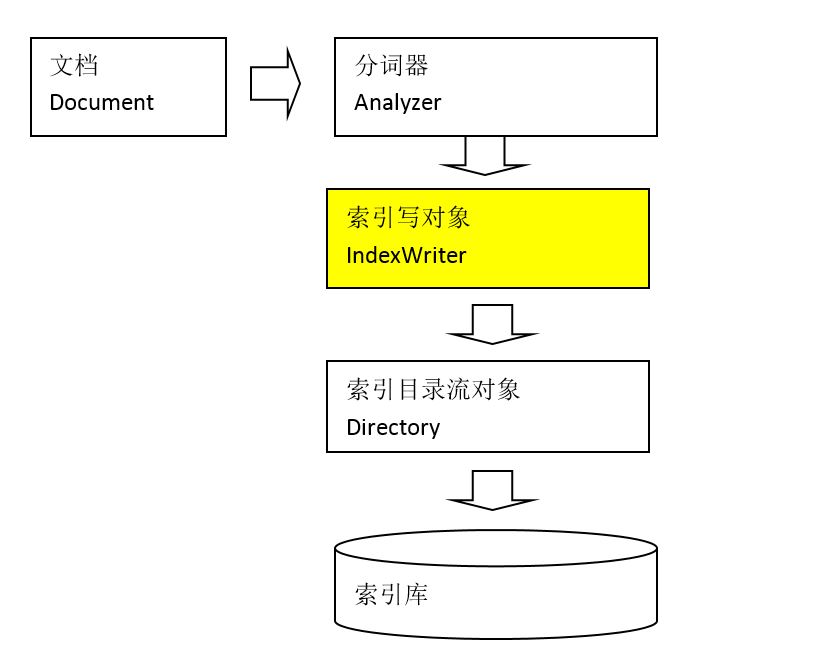
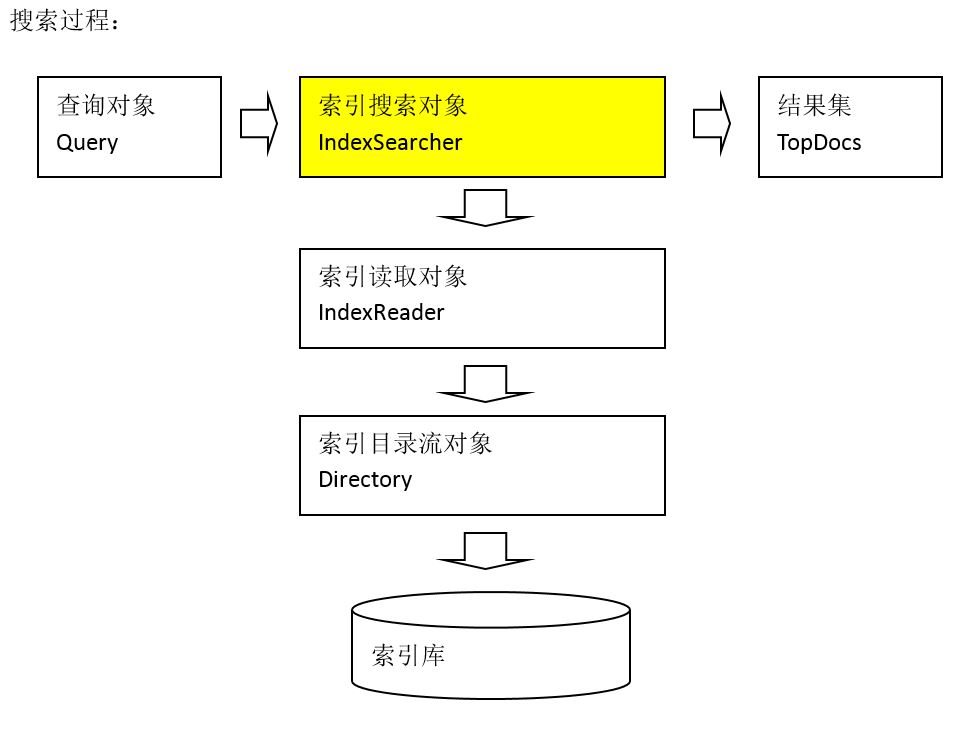
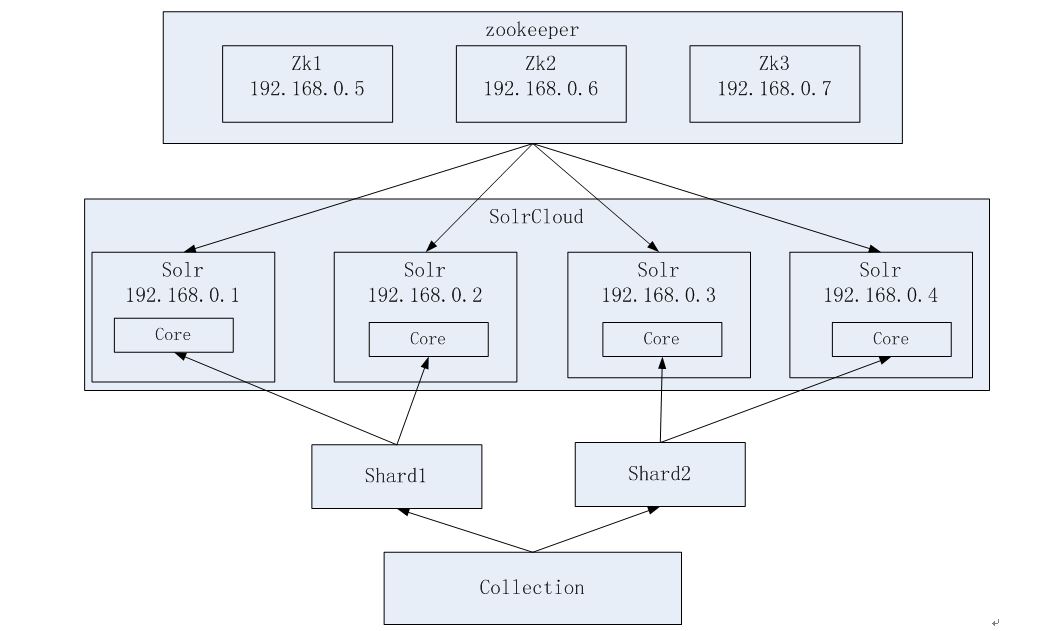
zookeeper微集群结构
Zookeeper
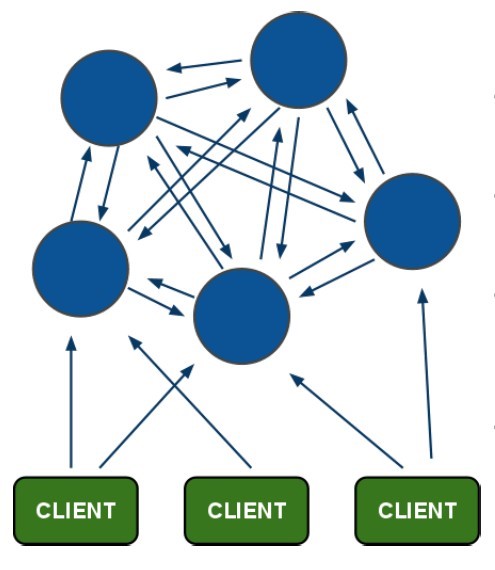
1、集群管理
主从的管理、负载均衡、高可用的管理。集群的入口。Zookeeper必须是集群才能保证高可用。Zookeeper有选举和投票的机制。集群中至少应该有三个节点。
2、配置文件的集中管理(这里使用)
搭建solr集群时,需要把Solr的配置文件上传zookeeper,让zookeeper统一管理。每个节点都到zookeeper上取配置文件。
Zookeeper集群搭建步骤
第一步.把zookeeper-3.4.6.tar.gz上传到服务,解压缩到/usr/local/目录下
第二步.在/usr/local/目录下创建solr-cloud目录,把zookeeper向该目录复制三份
cp -r zookeeper-3.4.6 /usr/local/solr-cloud/zookeeper01
cp -r zookeeper-3.4.6 /usr/local/solr-cloud/zookeeper02
cp -r zookeeper-3.4.6 /usr/local/solr-cloud/zookeeper03
第三步.配置zookeeper:
1.在zookeeper01目录下,创建一个data文件夹
2.在data目录下创建一个myid文件,内容为对应的id
echo 1 >> data/myid
在其他两个目录重复1,2两个步骤
3.修改conf文件,把zoo_sample.cfg文件改名为zoo_cfg
4.修改zoo.cfg
12行 dataDir=/usr/local/solr-cloud/zookeeper01/data
14行 01:2181,02:2182,03:2183
5.在zoo.cfg末尾添加服务地址
01:
server.1=0.0.0.0:2881:3881
server.2=115.159.93.201:2882:3882
server.3=115.159.93.201:2883:3883
02
server.1=115.159.93.201:2881:3881
server.2=0.0.0.0:2882:3882
server.3=115.159.93.201:2883:3883
03
server.1=115.159.93.201:2881:3881
server.2=115.159.93.201:2882:3882
server.3=0.0.0.0:2883:3883
第四步,启动zookeeper
到三个zookeeper目录的bin目录下,分别开启zookeeper服务
启动:./zkServer.sh start
关闭:./zkServer.sh stop
查看服务状态:./zkServer.sh status